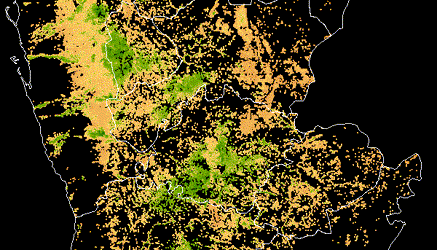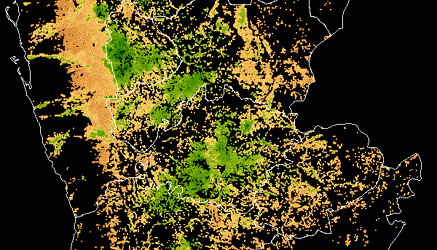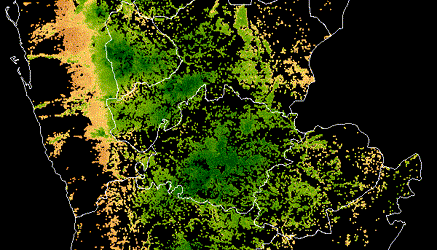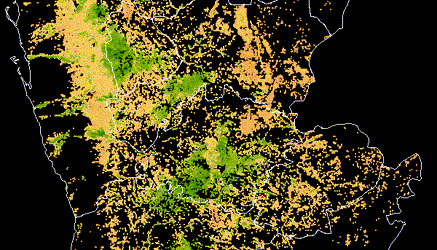
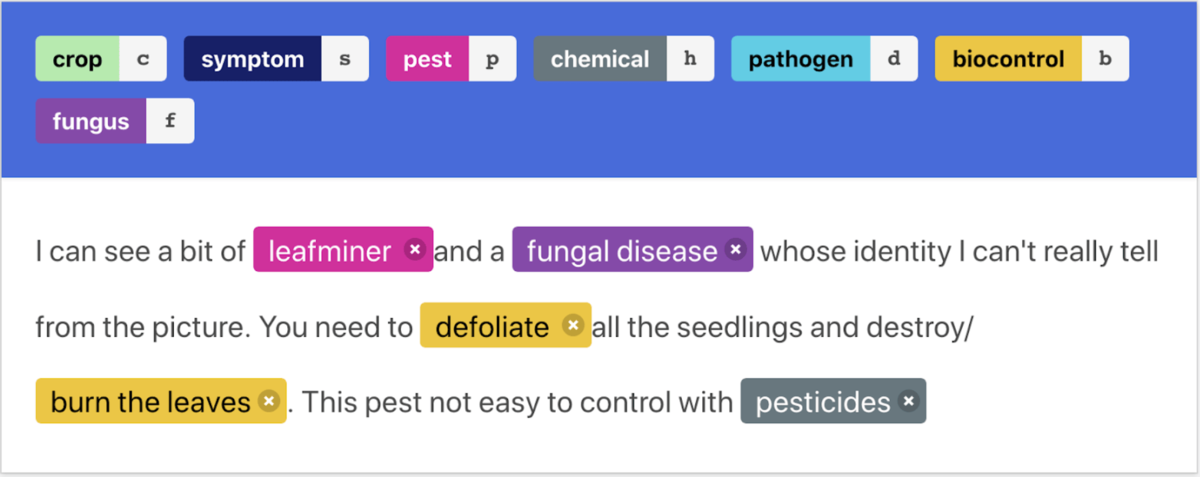
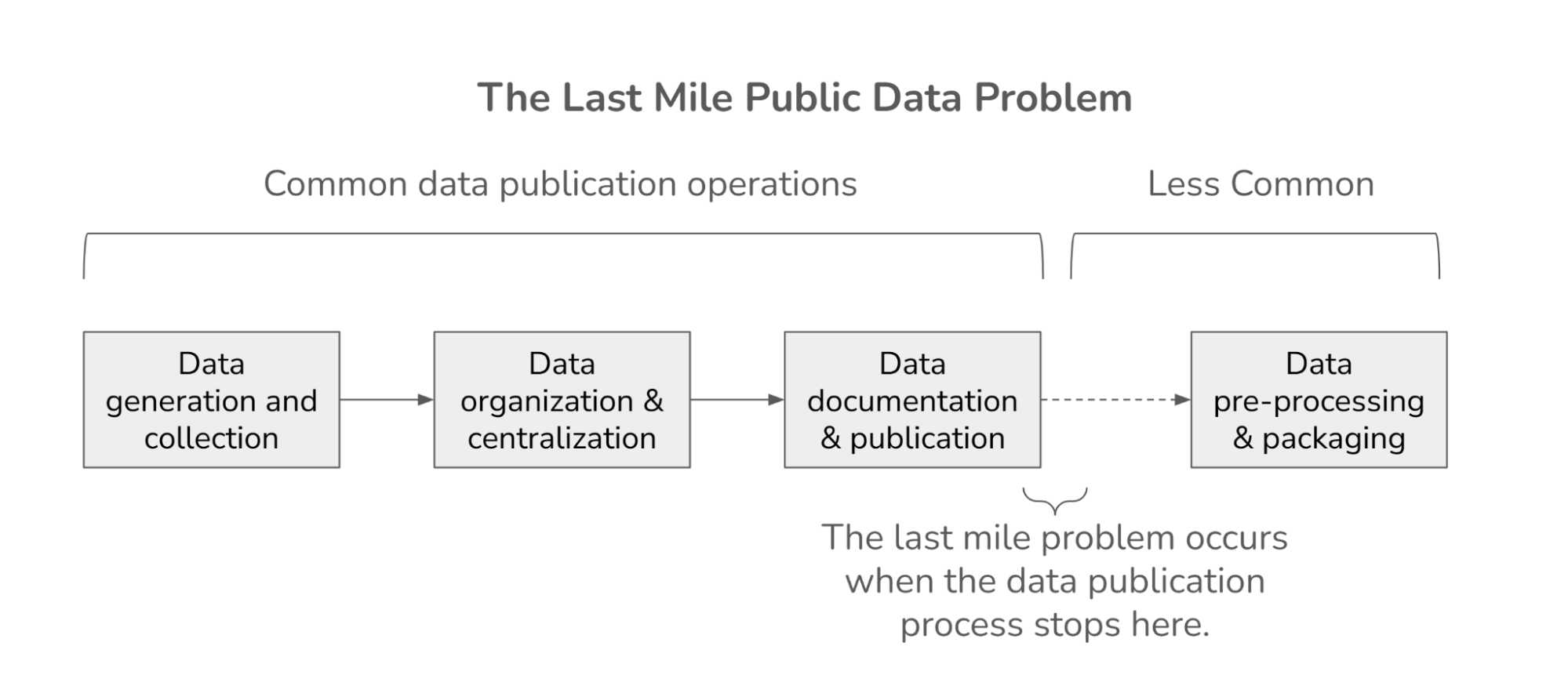
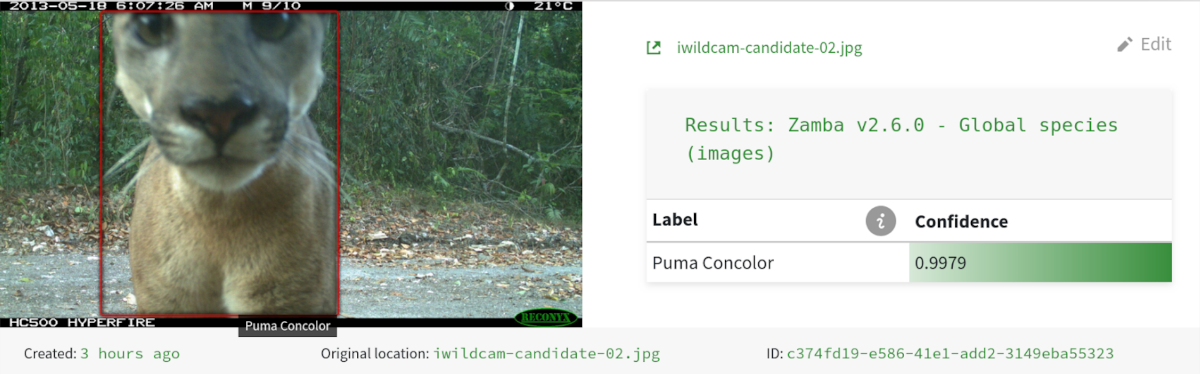
DrivenData is a social enterprise that works with mission-driven organizations to drive change through data science and engineering.
Challenges are one way we work with organizations to develop data science and AI solutions, by structuring problems so that a global community of experts can drive progress. We think it's a great option for suitable problems, and we've spent over a decade building out a competition platform and community that we're proud of.
We also know that competitions aren't right for every problem. For more flexible needs or sensitive data sources, we have our own team of experienced data scientists and engineers to take the case. Our team has extensive experience developing machine learning and artificial intelligence solutions, from exploratory research to advanced modeling to production systems, with a range of partners including Microsoft, Meta AI, NASA, Gates Foundation, and the World Bank.