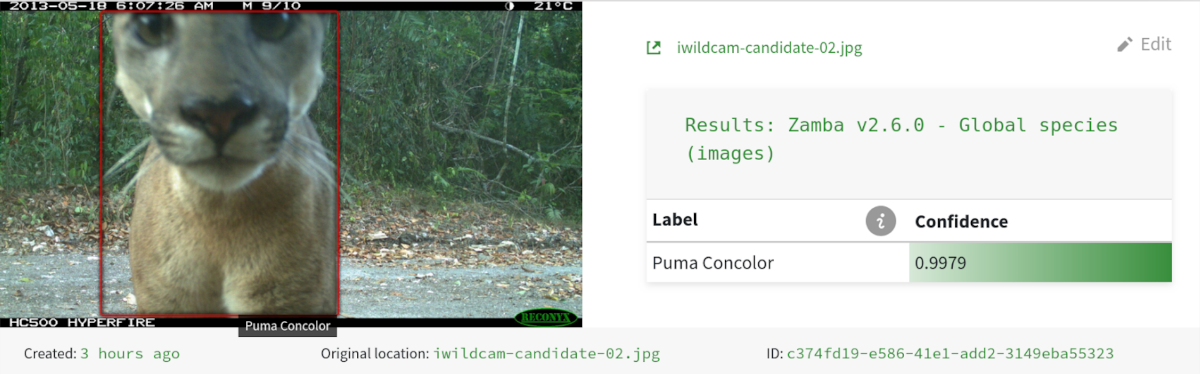
This was my first year attending the ASU+GSV Summit, and while I was excited to present our work on Automatic Speech Recognition (ASR) for children in the classroom, I wasn't quite prepared for the sheer scale of the event. Lines spilling out of session rooms, conference lunches vanishing in moments, and rooms so full of conversation that it is hard to hear yourself think. It's an environment brimming with ideas, and it's taken me some time to digest the whirlwind of interactions.
I had fascinating conversations, ranging from speaking with a pioneer who brought interactive AI systems to classrooms back in the late 1990s, to seeing Google researchers present sophisticated models assessed against comprehensive learning goals, to listening to a tense debate on squaring ChatGPT use with academic honor codes (is it a violation if I did the outline but not the writing?). Unsurprisingly, talks and conversations were liberally sprinkled with "AI" (and some folks may have been liberal with the A1 as well!).
The progress is undeniable, but amidst the excitement, I couldn't help but reflect on the critical pieces that will make this AI boom effective in the classroom.
The Data Bottleneck: Fueling AI Responsibly¶
AI models are only as good as the data they're trained on, and this presents a major hurdle in education. We're experiencing this firsthand in our work with ASR for children – the vast datasets scraped from the internet that train most commercial Large Language Models (LLMs) simply don't reflect the unique linguistic patterns, acoustics, and realities of a diverse classroom.
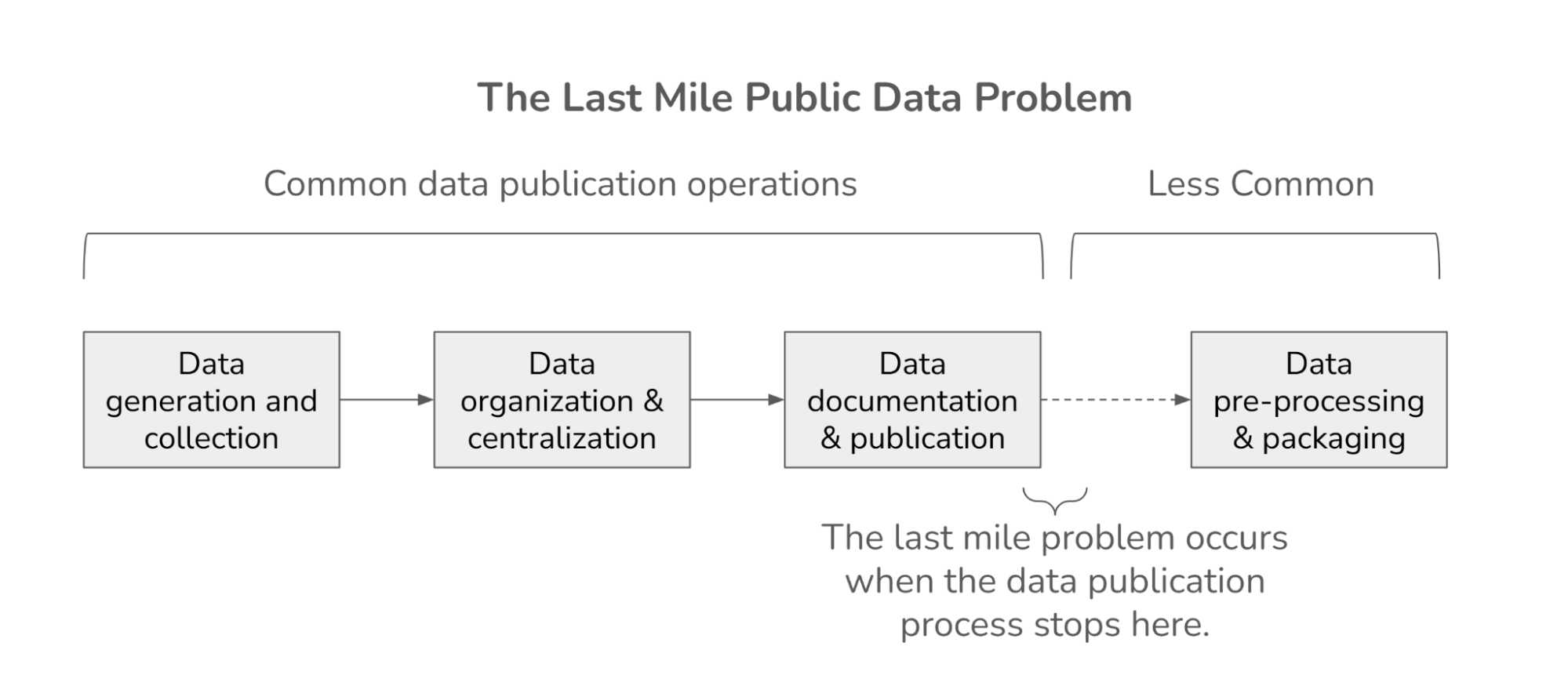
While this generation of students might be the most digitally documented, their data is often fragmented and locked away in aging Learning Management Systems, isolated research projects, or proprietary platforms. Bringing this data together ethically and effectively requires significant effort. We're undertaking this challenge for children's ASR data, but cleaning, annotating, and ensuring privacy is expensive and time-consuming. Off-the-shelf models trained on generic data will probably not work effectively or equitably in your specific educational context. Verification is crucial.
Evaluation: Moving Beyond the Checklist¶
On that point, evaluation was an emerging theme. Even if appropriate training data could be accessed, how do we rigorously assess if these AI tools actually work, and for whom?
Buying traditional software often involves a checklist that matches features to user needs. With AI, it's far more complex. An AI "feature" might work well for some students but fail, or even disadvantage, others with different backgrounds, learning styles, or in specific environments (e.g., a noisy classroom). AI buyers need evaluation frameworks that go deeper than surface functionality. This includes assessing performance across diverse student subgroups and understanding the potential for bias (we’ve been thinking about these kinds of biases for a long time—see our data ethics tool, Deon). We either need robust third-party auditing and evaluation, or buyers are going to have the get much more sophisticated in their evaluation approach.
Iteration vs. Fatigue: Finding the Right Pace for Innovation¶
The standard advice for building great AI is rapid iteration based on user feedback. This works well in many commercial sectors. However, education requires a more cautious approach. There is a real risk of inducing "study fatigue," a phenomenon that we have observed in fields like international development where communities become weary of constant experimentation without seeing clear benefits.
Students, teachers, and parents won't have infinite patience for endless cycles of testing AI prototypes in the classroom. We can't afford to treat schools like perpetual beta-testing labs. While iteration is necessary, experiments need to be structured for success from the outset, minimizing disruption and aiming quickly for demonstrable improvements in learning outcomes, rather than lingering in pilot purgatory.
The Cambrian Explosion and The Role of Public Goods¶
We're currently witnessing a Cambrian explosion of AI use cases in education – tools for tutoring, assessment, content generation, administrative support, and more. This rapid diversification is exciting, but it also increases the risk of the challenges mentioned above: data fragmentation, evaluation gaps, and study fatigue.
Public goods and infrastructure became a core focus of the panel I was on with Magpie Education, Learn FX, MRDC, Khan Academy, and the Bill & Melinda Gates Foundation. In an era dominated by powerful frontier models from major labs, investing in shared infrastructure for the sector—open datasets, open-source models, and open tools—is crucial. Our own work in ASR for kids aims to contribute exactly these kinds of public goods by collating data and annotating it so that a broader community can benefit. It’s clear that building blocks and infrastructure that are shared can help mitigate some of the externalities mentioned above of the Cambrian explosion of technologies being tested in the classroom.
I'd love to hear your reflections on the conference or these topics! What stood out to you? What challenges or opportunities do you see? Let’s work together to chart a thoughtful path forward.