The Challenge¶
Classroom observation videos provide valuable insights into a teacher's instruction, student interactions, and classroom dynamics. Over the past 15 years, their use in teacher preparation and the study of teacher quality has increased significantly. Despite this growth, using video at scale remains challenging due to the time and resources required for processing and analysis.
The goal of the Artificial Intelligence for Advancing Instruction (AIAI) Challenge was to build models that help automate classroom observation support so that it can be offered at scale and inform future teaching. Sponsored and organized by the Artificial Intelligence for Advancing Instruction Project and the University of Virginia, the challenge sought algorithms that could automatically label multimodal classroom observation data. Solvers developed machine learning models capable of identifying instructional activities and classroom discourse content from videos and anonymized audio transcripts. Given the sensitivity of classroom video data, the challenge was open only to participants affiliated with research institutions who could agree to strict data use agreements.

The challenge was organized into two phases. During the first phase, participants developed their models. They had access to a labeled training set for use in training their models and an unlabeled validation set against which to benchmark their progress. In the second phase, participants used their models to label new classroom observation data. They had a limited window of time to generate a set of predictions on an unseen and unlabeled test set consisting of videos and audio transcripts.
Model performance was evaluated according to macro-weighted F1-score that averaged performance across the 24 video instructional activity labels and 19 audio discourse labels. The metric intentionally weighted video classes slightly more than audio classes because there were more classes for videos. Final prize rankings were determined by performance in both phases, with Phase 2 performance contributing 75% and Phase 1 contributing 25%.
Results¶
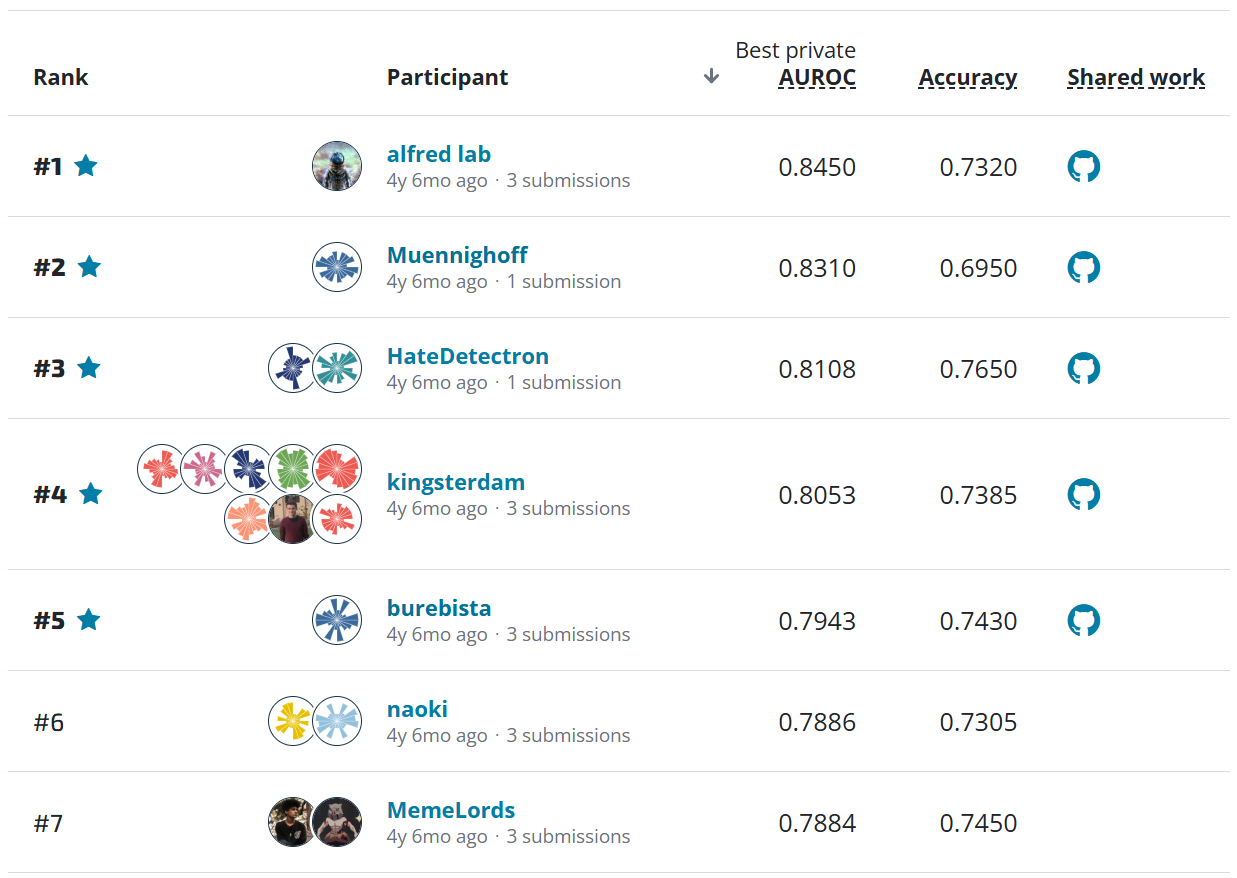
The competition evaluated final submissions from 9 teams consisting of 28 individuals from various academic backgrounds. The top three teams were broadly consistent in their performance within each category and overall across Phase 1 and Phase 2.
The top approaches met or exceeded the performance of provided benchmarks in most categories. All of the top submissions leveraged state-of-the-art transformer-based architectures for both video and text data, ensembling multiple models to improve performance. The top two solutions treated the video labeling and audio labeling as two distinct tasks, while the third place solution employed a step combining both modalities.
As shown in the table below, model performance varied across classes. For video activities, solutions were best at detecting teachers sitting, standing, or presenting with technology, while they struggled most with discerning whether students were talking with other students while on task as well as the method of teacher support given to students. For discourse content, solutions were best at identifying report requests and closed-ended questions, while they performed worst at identifying teachers giving explanations or justifications and asking task-related prompts.
The winning solutions in this competition pushed the boundary of the state-of-the-art in AI-assisted education, and established new collaborative networks among the organizers and winning teams. You can view the code from their solutions, which has been made available under a permissive open source license here. You can meet the winning teams and learn more about their approaches below!
| Final Macro-F1 Scores by Label | Team | ||||
|---|---|---|---|---|---|
| Label category | Label sub-category | Label | SALEN | TUM-UT | GoTerps |
| Activity | Discourse | On task student talking with student | 0.05 | 0.06 | 0.15 |
| Student raising hand | 0.77 | 0.73 | 0.22 | ||
| Representing Content | Individual technology | 0.46 | 0.25 | 0.11 | |
| Presentation with technology | 0.91 | 0.86 | 0.78 | ||
| Student writing | 0.66 | 0.61 | 0.41 | ||
| Teacher writing | 0.53 | 0.43 | 0.11 | ||
| Using or holding book | 0.73 | 0.52 | 0.32 | ||
| Using or holding instructional tool | 0.58 | 0.44 | 0.47 | ||
| Using or holding notebook | 0.38 | 0.27 | 0.05 | ||
| Using or holding worksheet | 0.74 | 0.72 | 0.53 | ||
| Student Location | Sitting at desks | 0.75 | 0.67 | 0.48 | |
| Students sitting at group tables | 0.87 | 0.78 | 0.36 | ||
| Students sitting on carpet or floor | 0.76 | 0.72 | 0.50 | ||
| Students standing or walking | 0.80 | 0.79 | 0.54 | ||
| Teacher Location | Teacher sitting | 0.93 | 0.92 | 0.84 | |
| Teacher standing | 0.91 | 0.90 | 0.61 | ||
| Teacher walking | 0.63 | 0.59 | 0.34 | ||
| Teacher Supporting | Teacher supporting multiple students with student interaction | 0.69 | 0.66 | 0.52 | |
| Teacher supporting multiple students without student interaction | 0.40 | 0.28 | 0.21 | ||
| Teacher supporting one student | 0.20 | 0.07 | 0.05 | ||
| Type | Individual activity | 0.19 | 0.15 | 0.13 | |
| Small group activity | 0.82 | 0.82 | 0.72 | ||
| Transition | 0.50 | 0.44 | 0.37 | ||
| Whole class activity | 0.78 | 0.71 | 0.60 | ||
| Discourse | Classroom Community | Feedback-Affirming | 0.68 | 0.66 | 0.64 |
| Feedback-Disconfirming | 0.46 | 0.40 | 0.37 | ||
| Feedback-Elaborated | 0.56 | 0.50 | 0.50 | ||
| Feedback-Neutral | 0.62 | 0.56 | 0.59 | ||
| Feedback-Unelaborated | 0.57 | 0.49 | 0.60 | ||
| Uptake-Building | 0.44 | 0.43 | 0.42 | ||
| Uptake-Exploring | 0.36 | 0.42 | 0.39 | ||
| Uptake-Restating | 0.53 | 0.51 | 0.54 | ||
| Cognitive Demand | Analysis-Give | 0.48 | 0.38 | 0.33 | |
| Analysis-Request | 0.55 | 0.50 | 0.55 | ||
| Report-Give | 0.52 | 0.31 | 0.45 | ||
| Report-Request | 0.82 | 0.70 | 0.77 | ||
| Explanation / Justification | Student-Give | 0.64 | 0.57 | 0.63 | |
| Student-Request | 0.51 | 0.56 | 0.42 | ||
| Teacher-Give | 0.30 | 0.24 | 0.26 | ||
| Teacher-Request | 0.62 | 0.57 | 0.55 | ||
| Questions | Closed-Ended | 0.73 | 0.63 | 0.67 | |
| Open-Ended | 0.53 | 0.51 | 0.55 | ||
| Task Related Prompt | 0.26 | 0.31 | 0.12 | ||
The performance of each winning solution on each sub-category in each phase.
Meet the Winners¶
SALEN¶

Team members: Jie Tian
Place: 1st Overall
Prize: $40,000
Usernames: SALEN
Background:
I am a surgical resident at NanFang Hospital affiliated with Southern Medical University, and my research field is computer-assisted medicine.
Summary of approach:
Although the task is most naturally aligned with multimodal Temporal Action Localization, we simplified it to a multi-label binary classification problem on fixed-duration segments due to poor audio-video correspondence and task complexity constraints. We modeled the Activity component and Discourse component as two independent, non-interfering tasks: the Activity component accepts only video input, while the Discourse component processes only text input. Building upon this foundation, we meticulously designed comprehensive data sampling and augmentation strategies, along with extensive regularization methods to address severely imbalanced labels.
For the Discourse component, we fine-tuned Qwen3 models using 8B, 14B, and 32B parameter variants. We employed the ModelScope-Swift framework, utilizing its built-in sequence classification functionality to convert the pretrained LLM from a generative model to a sequence classification model. For each input sequence, we directly trained on the 19 binary classification labels using Binary Cross-Entropy (BCE) loss.
We selected the pretrained InternVideo2-1B as our base model—a 1B-parameter video Vision Transformer pretrained on the Kinetics-710 dataset for video action classification. Originally designed to process 8 RGB video frames during pretraining, we extended the model to handle longer temporal windows and finer-grained frame intervals to maximize input information. We achieved this by applying linear interpolation to the temporal position encodings in the embedding layer, enabling the model to process 16-frame video inputs.
Check out SALEN's full submission in the challenge winners repository.
TUM-UT¶




Team members: Ivo Bueno, Ruikun Hou, Dr. Babette Bühler, Dr. Tim Fütterer
Place: 2nd Overall
Prize: $20,000
Hometowns: Curitiba, Brazil; Shandong, China; Fürth, Germany; Tübingen, Germany
Usernames: ivo.bueno, ruikun_hou, babette, tillfuetterer
Background:
Dr. Tim Fütterer is a Postdoctoral Researcher at the Hector Research Institute of Education Sciences and Psychology, University of Tübingen. His research focuses on technology-enhanced teaching and learning, teacher professional development, and the application of artificial intelligence for assessing and improving teaching quality. He has held visiting positions at Stanford University and the University of Oslo and is actively engaged in international research networks such as the European Association for Research on Learning and Instruction (EARLI).
Dr. Babette Bühler is a postdoctoral researcher at the Chair of Human-Centered Technologies for Learning at the Technical University of Munich. She holds a Dr. rer. nat. in Computer Science from the University of Tübingen, where she conducted research at the Hector Research Institute of Education Sciences and Psychology and is a member of the LEAD Graduate School & Research Network. Her research lies at the intersection of artificial intelligence and research on education, with a focus on multimodal machine learning to assess cognitive and behavioral processes during learning.
Ruikun Hou is a doctoral student at the Chair of Human-Centered Technologies for Learning at the Technical University of Munich. His research applies machine learning techniques to educational settings, with a particular focus on multimodal classroom observation and the automated assessment of teaching quality.
Ivo Bueno is a doctoral candidate at the Chair of Human-Centered Technologies for Learning at the Technical University of Munich. He holds a Master’s degree in Computational Linguistics from LMU Munich. His research lies at the intersection of machine learning, natural language processing, and multimodal AI, with a focus on fostering effective and ethical interactions between humans and intelligent systems. In his doctoral research, he explores human-centered AI by combining insights from computational linguistics, federated learning, and privacy-enhancing technologies to develop more inclusive and intelligent learning systems.
Summary of approach:
We developed separate models for vision and transcript labels, tailored to each modality’s characteristics. For vision labels, we explored both zero-shot annotations using Qwen2.5-VL-32B and fine-tuning V-JEPA2 video transformers to address this multi-label classification problem. The final solution used an ensemble approach, selecting the best-performing model for each label based on validation F1. For discourse labels, we generated a previous context of size two for each transcript, and then ran it through DeBERTa-V3 for embeddings, and a single Linear Layer for classification. Focal loss was used to help counter the class imbalance.
Check out TUM-UT's full submission in the challenge winners repository.
GoTerps¶





Team members: Wei Ai, Meiyu (Emily) Li, Jiayuan Shen, Hjooyun (Rosalyn) Shin, Jiseung Yoo
Place: 3rd Overall
Prize: $10,000
Usernames: aiwei, meiyuli, jshen20, rhjshin, yjiseung
Background:
Wei Ai is an Assistant Professor in College of Information at the University of Maryland, who develops end-to-end data science solutions that combine machine learning, causal inference, and field experiments. His current research focuses on using AI to identify, measure, and promote effective teaching practices in K-12 education.
Meiyu (Emily) Li is a PhD student in Information Studies at the University of Maryland, working in the Computational Linguistics and Information Processing Lab. Her research focuses on developing machine learning and natural language processing techniques in the field of education.
Jiayuan Shen is a Masters student in University of Maryland, focusing on machine learning and their applications in education
Hjooyun (Rosalyn) Shin is a PhD student in Technology, Learning, and Leadership (TLL) program at University of Maryland, College Park. Her main research interest is on developing AI-integrated learning and teaching technology that provides equity-oriented STEM education for students of different backgrounds and abilities.
Jiseung Yoo is a PhD student in Educational Policy at the University of Maryland's College of Education. Her research interests include using data science to support teacher collaboration and exploring how AI-powered tools affect teacher-student interaction and relationship-building.
Summary of approach:
Our approach combines text and video modalities using an ensemble approach. On the text side, we preprocess each target turn with multi-context conversation windows using 3, 5, and 7 prior turns to give the model short-range discourse context. We train an ensemble of five transformer classifiers (three using RoBERTa-base and two using DeBERTa-v3-base) with a weighted loss, then aggregate predictions via category-level majority voting with tie-breaker logic.
For video, we use a VideoMAE backbone (MCG-NJU/videomae-base) fine-tuned for multi-label visual classification of classroom activities. We employ weighted sampling during training to counter class imbalance.
Check out GoTerps' full submission in the challenge winners repository.
Thanks to all the challenge participants and to our winners! And thank you to the Artificial Intelligence for Advancing Instruction Project and the University of Virginia for sponsoring this challenge!